The GLM as a Means to Ensure Statistical Validity
This was published a little while ago, but I haven’t had a chance to share it until recently: my article in the International Journal of Digital Humanities! It tackles a challenge I’ve seen many of us in the Digital Humanities (DH) dealing with, something I’ve been thinking about for a while. Namely, how do we ensure our quantitative research stands up to scrutiny? In 2019, Nan Z. Da published an article in Critical Inquiry entitled “The Computational Case against Computational Literary Studies.” The response was a fierce debate about the validity of quantitative methods in the humanities. In response, Critical Inquiry hosted an online forum to discuss some issues. The responses often focused on some of Da’s errors in her critique. Still, I think the real issue is that many of us in DH and the humanities, more broadly, lack the statistical training to conduct quantitative research effectively.
In response, my article centers on two key points: the General Linear Model (GLM) and what I call a “minimal research compendium.” Think of the GLM as a statistical superhero - it’s the tool I wish someone had shown me years ago! Like a Swiss Army knife, it can tackle many tasks related to data analysis and underlies many statistical techniques like t-tests, ANOVAs, and regressions. By centering statistical training around the GLM, DH scholars can streamline statistical learning while ensuring a robust foundation for analyzing a wide range of data. Instead of getting bogged down by memorizing numerous tests and their specific applications, they can gain a deeper understanding of the underlying principles governing statistical relationships, which will allow them to build a strong foundation. Perhaps most importantly, I also focus on the importance of residual plots, which are essential for checking the assumptions using the easystats package. These plots can help identify potential issues with the model, such as non-linear relationships or heteroscedasticity, which can lead to incorrect conclusions.
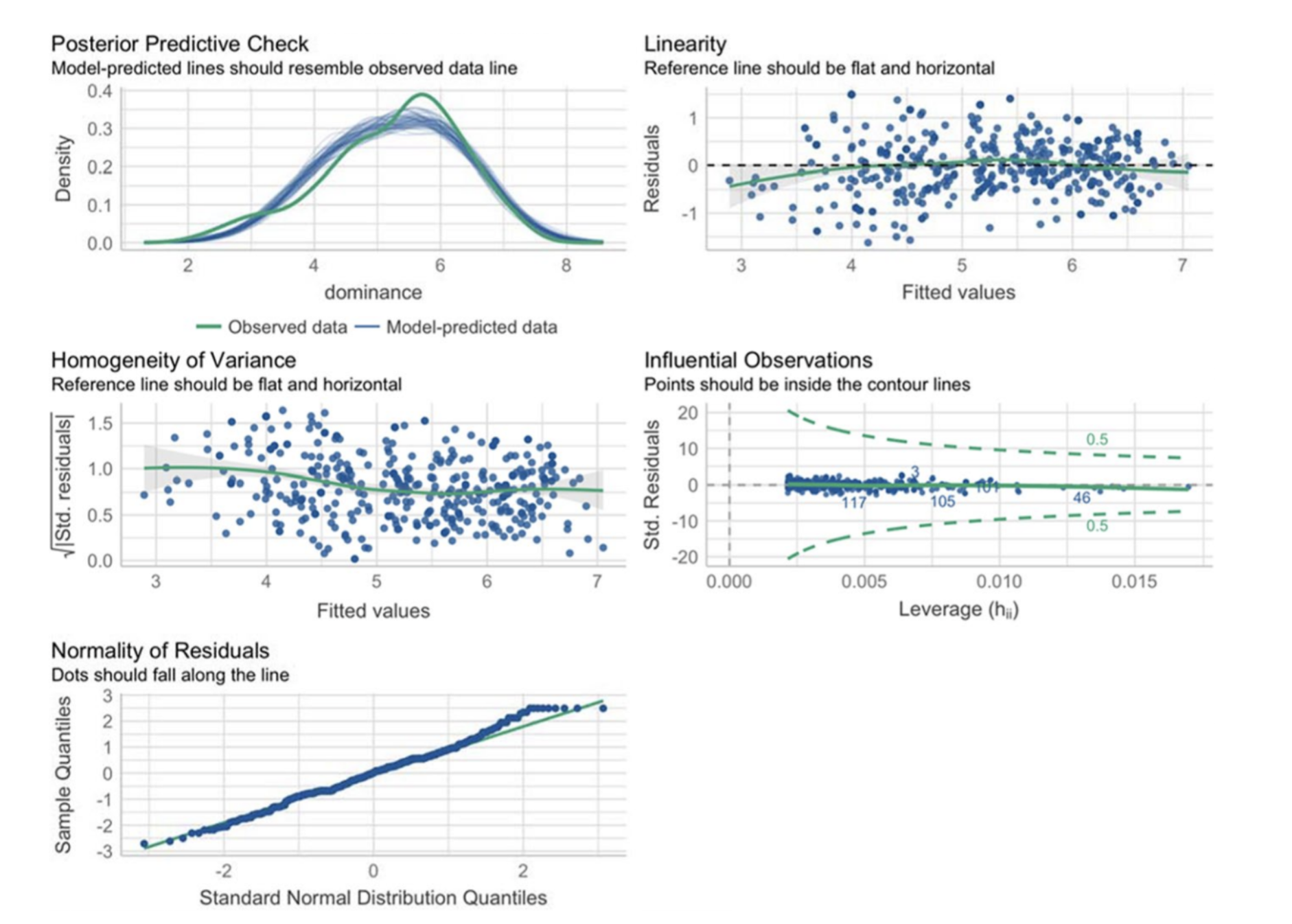 Example of a residual plot developed through the easystats package.
Example of a residual plot developed through the easystats package.
A key benefit of focusing on a statistical test is that it can be incorporated into a reproducible workflow, which is essential for ensuring the validity and transparency of research. This is where the concept of a “minimal research compendium” comes in. It’s a simple, transparent method for documenting statistical analysis, ideally using a platform like R. This includes details about the computing environment, data handling steps, GLM implementation, and, crucially, the residual plots, which help check the GLM assumptions. Admittedly, my idea of reproducibility is less stringent than others. My goal is more oriented towards ensuring that media archeologists and historians have the information necessary to replicate the analysis later, even if it involves using emulators or other tools, rather than the need for scholars to try to reproduce the analysis in the immediate future. Perhaps this is a bit of a cop-out, but it’s a good starting point for many scholars just beginning to engage with quantitative methods.